I’ve long authored this blog in WordPress because I’ve found the interface homely and easy to maintain. However, with the advent of cheaper external devices like Raspberry Pis, I wanted to move to a static site and host the website via CDN at my own IP dynamic address, eschewing the need for using expensive hosting solutions. The end goal for this was to move to a more self-rolled knowledge base website where I could store posts in a filesystem hierarchy rather than in a database.
Here’s how I migrated.
Proof of concept post
Generating a test blog post
As I didn’t want to write pure HTML as I felt it led to a bit of an unstructured format that couldn’t be parsed later or used for heavy cross-linking, I explored some options for authoring the files.
reStructedText
First I considered reStructuredText. This is a markup format that was originally created to write Python docs and later, due to its flexibility, became popular for authoring other types of documents. Here’s what a basic *.rst file looks like.
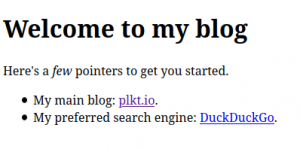
==================
Welcome to my blog
==================
Here's a *few* pointers to get you started.
- My main blog: `plkt.io/ <https://plkt.io//a>`_.
- My preferred search engine: `DuckDuckGo <https://ddg.co>`_.
It can be converted into HTML with pandoc.
$ pandoc –tab-stop 2 -f rst -t html sample.rst
<h1 id="welcome-to-my-blog">Welcome to my blog</h1>
Here's a <em>few</em> pointers to get you started.
<ul>
<li>My main blog: <a href="https://plkt.io//a">plkt.io/</a>.</li>
<li>My preferred search engine: <a href="https://ddg.co">DuckDuckGo</a>.</li>
</ul>
A very clear and straightforward way to write blog posts in the terminal but I felt I wasn’t really getting that much more of an advantage from writing directly in the WordPress text editor because there wasn’t any semantic mark up.
DocBook
Next, I looked up DocBook which is heavily used as an authoring format for writing books and technical documents. As this is the primary content on this blog, it seemed worth exploring. At first, I saw many old examples online of how to author a simple document and was immediately horrified by the referenced to the Document Type Declaration (DTD) that harkens from old HTML+XML days.
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE article PUBLIC '-//OASIS//DTD DocBook XML V4.5//EN'
'http://www.oasis-open.org/docbook/xml/4.5/docbookx.dtd'>
<article lang="en">
<title>Sample article</title>
<para>This is a very short article.</para>
</article>
Fortunately, according to the latest DocBook 5.0 standard, this arcane incantation wasn’t required and what we have today is something like this, notice the xmlns portion of the article element. As a side note, I found out that the Linux Kernel documentation has started migrating away from DocBook to using Sphinx + reStructuredText. Read more about this here.
<?xml version="1.0" encoding="utf-8"?>
<article xmlns="http://docbook.org/ns/docbook" version="5.0" xml:lang="en">
<title>Sample article</title>
<para>This is a very short article.</para>
</article>
So, after spending about 30 minutes using the documentation, I managed to re-write the *.rst example above into the following.
<?xml version="1.0" encoding="utf-8"?>
<article xmlns="http://docbook.org/ns/docbook" version="5.0" xml:lang="en"
xmlns:xlink="http://www.w3.org/1999/xlink">
<info>
<title>Welcome to my blog</title>
</info>
<section>
<title>Welcome to my blog</title>
<para>Here's a <emphasis>few</emphasis> pointers to get you started.
</para>
<itemizedlist mark='dash'>
<listitem>
<para>My main blog <link xlink:href="https://plkt.io//a">plkt.io/</link>
</para>
</listitem>
<listitem>
<para>My preferred search engine <link xlink:href="https://ddg.co">DuckDuckGo</link>
</para>
</listitem>
</itemizedlist>
</section>
</article>
Quite a bit more verbose and a bit of a pain to type in Vim. Omni-completion C-X,C-O helped a lot in closing tags. I can understand a bit better why reStructuredText, although not as structured as this, reduces the initial hump to get started so will likely result in more up to date documentation.
Selecting a winner
From the explorations above, I finalised the decision on reStructuredText for the mark up format. However, before fully embracing the format, I needed to land on the structure of the site. I had decided that the content itself would serve as the structure rather than living within the structure. Put another way, I decided that one would read my content to determine the taxonomy rather than the content be defined by the taxonomy. This meant that hyperlinking would be very important (and very manual) so I would need to make a stronger effort to keep related documents connected to each other.
Organisation
I envisioned my static site to enventually converge to something resembling a MediaWiki site.
The structure would be like this:
-
root
-
wiki or kb (knowledgebase) for evolving content
- about
- contact
- pub(lications) for posts
- store file store for media
- history for archival record of pages
- git for git repositories
-
wiki or kb (knowledgebase) for evolving content
This seemed like a good first pass for the organisation and something that I could change in the future without too much effort.
Creating the base site
I created the base directory structure and started defining the metadata for the site. As I was using pandoc, this would be split across three files: the template file for the HTML generator, the metadata file to contain variables across the entire site, and the YAML metadata at the top of each *.rst file that contained file specific references.
As Pandoc doesn’t support YAML headers in *.rst files (yet, see here) I’m storing all my YAML metadata in a side file called *.yaml for each post. While it’s not ideal, it’s simple and maintainable in the makefile.
Makefile
It took me a couple hours to walk through the documentation and build this makefile. However, I feel that as this project becomes more complicated this will pay off. Here’s what I came up with as a basis.
# Makefile for plkt.io/
VERSION = 0.1
PANDOC := pandoc
FIND := find
PANDOCOPTS := –tab-stop 2 -s –template ./template.txt -f rst -t html -M “lang: en” -M “css: ./style.css” -B header.html -A footer.html
# Note that $(shell <>) replaces newlines with spaces.
dir := ./
src := $(shell $(FIND) $(DIR) -name “*.rst”) # TODO: Do this using make rules.
targets_html := $(src:.rst=.html)
%.html: %.rst
@echo “Compiling” $<
@$(PANDOC) $(PANDOCOPTS) –metadata-file=$(basename $<).yaml $< > $@
all: build
build: $(targets_html)
# Not yet implemented. Supposed to build the site and tar it up for distribution.
dist: clean build
mkdir -p plkt-${VERSION}
for html in $(targets_html); do \
mv $$html plkt-$(VERSION)/; \
done
tar -cf plkt-${VERSION}.tar plkt-${VERSION}
gzip plkt-${VERSION}.tar
rm -rf plkt-${VERSION}
.PHONY: clean
clean:
@for html in $(targets_html); do \
echo “Cleaning” $$html; \
rm -f $$html; \
done
Headers and footers
Each file would need a header and footer to maintain some visual consistency across the site. To do this, I referenced the header with the -B flag and the footer with the -A flag.
Setting up apache
For the proof of concept, I opted to not use containerisation and instead just move the *.html and *.css files into the /var/www/html directorie. Viewing the website at http://localhost:80 worked admirably.
Migrating the post history
Exporting the posts from WordPress was a bit tricky. I first tried to use Pandoc’s automatic converting functionality but then I realised I’d have to do it twice: download the HTML, convert to reStructuredText, and then convert it back to HTML.
pandoc -f html -t rst https://plkt.io/2019/11/30/returning-to-wordpress/
I then landed upon a better method. I modified the template for my website by removing the header, footer, and post listing, visited each page individually, and saved them using Firefox. This took about 15 minutes (probably less time that automating it). Then I shoved the posts into a “archived posts” category that I would move bit by bit into the reStructuredText format.
Summary
This exercise taught me a lot about the data storage formats. What is the right way to store my post history? — Should it be a multiplicity format that separates the presentation from the data or should each post stand the test of time as its own standalone file? I’m starting to lean towards the latter. I think it’s possible to have the best of both if scoped properly by having an “archive” section of your site. So go ahead and export that page and leave it up for eternity. Normal visitors can view your normal site with the latest formatting but patreons of antiquity can learn more about the cake is made.
This will be the last post written using WordPress. The next post on this site will be generating using pandoc and Vim :).